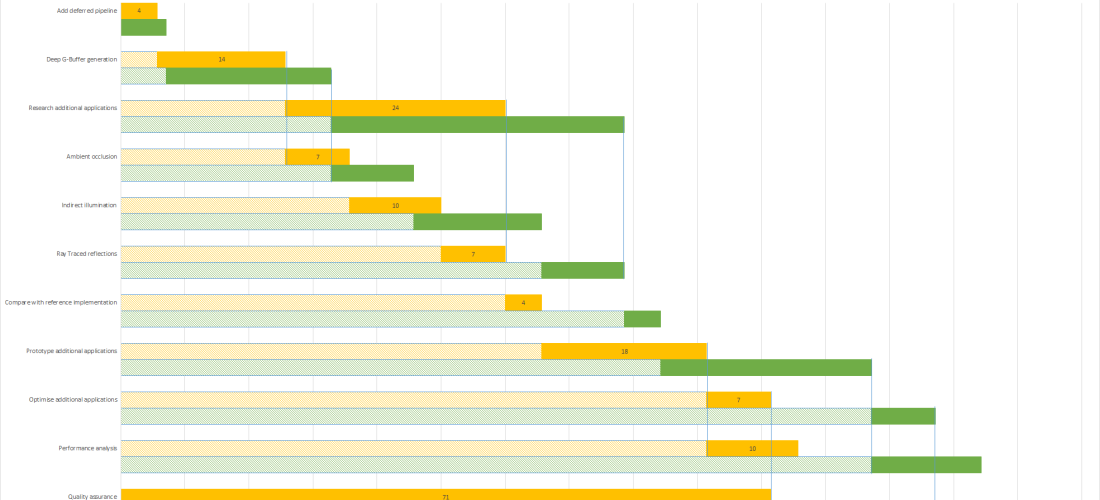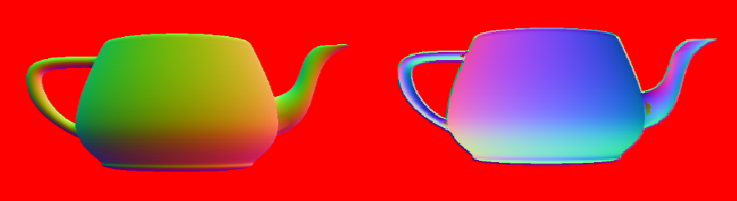
At the start of the week, I spoke about my current progress with the project. I briefly covered deep G-Buffer generation basics. I will now dive a little deeper and give a few more details on just how the algorithm works. Including some in-engine screenshots.
Just as a disclaimer before we begin. All of this information comes directly from the original papers and project source code. What I describe here is all available there in more detail.
So last week I talked about how the rendering is set up. I mentioned how with DirectX we can draw to multiple render targets from a single shader. I also mentioned that when working with deep G-Buffers each render target holds an array of textures that we draw each of our layers to (i.e. RenderTarget1[0] Holds the diffuse colour for the first layer of objects and RenderTarget1[1] Holds the diffuse colour for the second layer of occluded objects).
To split our scene into layers we need to be able to detect in our pixel shader which objects to draw to our second layer. To do this we can take the depth of the first layer and compare the depth of the current fragment with the depth at the same coordinates in the first layer. If the current fragment is further away from the camera then we can draw it otherwise the fragment is discarded. Now this works fine if we are generating our deep G-buffer over multiple passes as we can take the depth buffer from the first pass and use it in our second pass. However, we want to generate both layers in a single pass meaning we don’t have access to the first layers depth buffer for this frame. So, how do we overcome this? A few different techniques are presented in the paper that solve this issue, the one I will be explaining here is the reprojection method.
The reprojection method works by sampling the depth from the previous frame. As you can imagine during fast movement this will cause artefacts as the sampled depths from the previous frame no longer accurately represent the depth in the current frame. So what we do to overcome this, is take the transforms from the previous frame to calculate how much the current fragment has moved allowing us to sample accurate depths from the previous frame. This can still cause issues around fast moving objects but for most cases, this technique gives us the most accurate separation. One other technique worth mentioning is the delay technique. This adds an additional frame of latency giving us access to the vertex positions for frame t+1. Allowing us to perfectly predict the depth of the first layer. Although this always produces the correct result it does require adding that additional latency which is often best avoided. Since we are just rendering stuff and there is little user interaction the latency would likely not be very noticeable. However, we want to re-create what they produced in the paper so we will continue to use the reprojection method. We will make use of the screen space velocity for other effects so that’s an extra bonus.
The pipeline for generating the deep G-Buffer looks something like this.
Vertex Shader
Calculate camera space position for the current frame.
Calculate camera space position from the previous frame.
As usual, calculate the projected screen space position of the vertex.
Calculate application specific values
Geometry Shader
For each layer
For each vertex
Copy vertex data and add new vertex to new triangle
Submit the new triangle to the pixel shader
Pixel Shader
Calculate screen-space velocity of current pixel using positions from this and the previous frame
If we are drawing to the second layer
Using reprojected screen space coordinate sample depth from the previous frame
If the current pixel depth is less than the previous depth + minimum separation
Discard pixel
Output data to G-Buffer
The implementation can be found on the project GitHub here.
Below you can see both layers of the camera space normals render target. Here we are still rendering back faces to demonstrate the results of the algorithm. We will eventually cull all back faces as you can imagine access to the internal faces of an object is not all that useful.
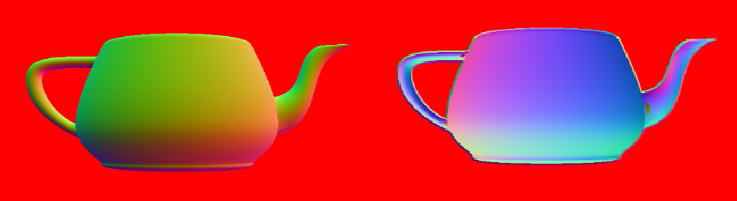
I will begin work to try to import more complex scenes. The current implementation works well for this single object, but needs to be tested for more complex scenes. Following that I want to add some additional debug tools to make it slightly easier to view the different layers of the different render targets from the deep G-Buffer. This will then put me in a good place to begin implementing the screen-space effects utilising the deep G-buffer.